Optimizing Qt for MIPS: QString::fromLatin1
27 February 2013
During the last months at Igalia we have been working on optimizing open source components for the MIPS architecture, using the SIMD instructions supported by the latest MIPS 74K cores. More specifically, I have been working on the Qt framework.
One of the most used parts of Qt are the basic utilities in the QtCore
module, being QString a basic building block that all applications are
expected to use heavily, so making it faster would be a gain for any
application. One of the functions I first worked on is
QString::fromLatin1: it converts an array of characters in
ISO–8859–1 encoding (also known as “Latin 1”) and returns a QString
object, which internally stores text data in UTF-16.
Let’s take a look at the generic version of QString::fromLatin1.
Taking apart the surrounding code, the loop contains a simple “pull-up”
operation: each input byte is converted to an unsigned 16-bit integer,
padding the high 8 bits with zeroes (the method works for ISO–8859–1, do
not try this for other input encodings):
// "dst": array of 16-bit integers
// "src": array of 8-bit integers
while (len--)
*dst++ = (uchar) *src++;
Almost every compiler out there —including GCC— will implement this doing 1-byte loads into a register, zeroing the upper part of the register, and then doing a halfword (16-bit) store. Essentially:
; a0: "dst" array
; a1: "src" array
; a2: "len"
1: lbu t1, 0 (a1)
addiu a2, a2, -1
sh t1, 0 (a0)
addiu a0, a0, 2
bnez a2, 1b
addiu a1, a1, 1
(Note how the branch delay slot is taken advantage of to increment
one of the pointers; some compilers may just insert a nop instead.)
The most important thing to do is unrolling the loop, but some care is needed: as Thiago Macieira mentions in one of his articles, in average most of the strings in Qt have a length of 17 characters. This means that doing a long unrolling of the loop could be worse because of the calculations needed to determine how many times the unrolled loop is executed and the handling of the remaining items. The first thing to do was making two versions of the algorithm: one with the loop unrolled 4 times, the other with it unrolled 8 times.
As next step, the usual optimization is changing the memory access so as load/store operations are aligned, and handle full words (instead of bytes and halfwords). Loading a word means that the loop is implicitly unrolled 4 times, and some bit-juggling needs to be done in order to extract the values before storing them. Something like:
1: lw t1, (a1) ; t1=ABCD
addiu a1, a1, 4
; extract bytes from t1 to t2/t3, padding
; them with zeroes: t2=0A0B, t3=0C0D
addiu a2, a2, -4
sw t2, 0 (a0)
sw t3, 4 (a0)
bnez a2, 1b
addiu a0, a0, 8
If the code needed to unpack the data needs more than 14 instructions,
then this loop would use more instructions than the basic one above
(maybe it still would be marginally faster due to the aligned
load/store). This is where the new DSP instructions of the 74K cores
come in handy: the preceu.ph.qbl and preceu.ph.qbr instructions
unpack two 8-bit parts of a register to two 16-bit integers in another
register. Like this:
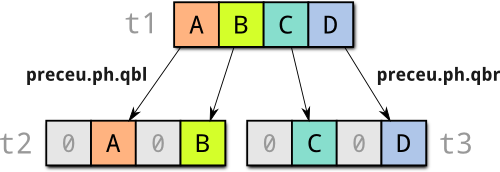
Using the preceu.ph.* instructions avoids having to do quite a lot of
shifting and masking to get the values right. The final loop is still
quite easy to grasp:
1: lw t1, (a1) ; t1=ABCD
addiu a1, a1, 4
preceu.ph.qbl t2, t1 ; t2=0A0B
preceu.ph.qbr t3, t1 ; t3=0C0D
addiu a2, a2, -4
sw t2, 0 (a0)
sw t3, 4 (a0)
bnez a2, 1b
addiu a0, a0, 8
Note that the actual implementation is longer, handles the extra items remaining after the unrolled loop, and has a preamble to make the pointers aligned—which, most of the time, is worth to do.
For the sake of completeness I made an additional version of the function in assembler with the loop unrolled 8 times, which uses byte loads and halfword stores. For the benchmarking different string lengths were checked, being each version of the function called a million times. The plot uses the average of 10 runs:
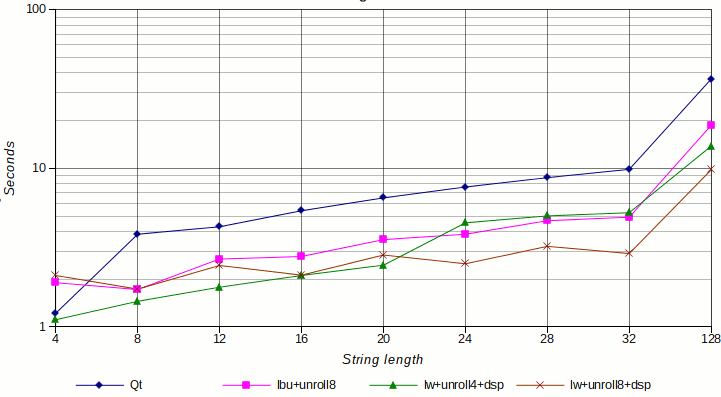
Legend for the plot above:
Qt: This is the original code included in Qt, which is s simple pull-up operation that converts chars to short integers. The code was built with-O2 -march=74kf -mdspr2to get the best possible optimizations from GCC.lbu+unroll8: Loads each character usinglbu(byte load) instructions, stores results usingsh(store halfword), and the main body of the loop is 8-unrolled. It also uses cache prefetch hinting for both source and destination memory areas.lw+unroll4+dsp: The main body of the loop is 4-unrolled, usinglwinstructions to load aligned words, DSP instructions to unpack bytes into halfwords, and finally store results withswinstructions.lw+unroll8+dsp: Similar to the previous one, main body is 8-unrolled, and if the source address is not aligned, up to three bytes are consumed before starting to uselwinstructions to load aligned words.
The following observations can be done:
- All the optimized versions perform better than the simple Qt version, being the speedup up to 3.x (note: the time scale in the graphic is logarithmic).
- For strings up to 20 characters, the 4-unrolled function performs clearly better, because of the small data set and the fact that it avoids the additional preamble used to align the source pointer address. Also, some string lengths (4, 12, 20) can be better handled by the 4-unrolled loop because the lengths are not divisible by 8.
- For strings bigger than 20 characters, the 8-unrolled with aligned loading version is the best, and it reaches a 3x speedup for strings longer than 32 characters. For longer strings, the speedup is maintaned and becomes clearer as string are longer.
With this data, we can conclude that the best implementation is an
hybrid approach, using both the code for the 4-unrolled loop and the
8-unrolled loop, and selecting one of them depending on the length of
the input data. Checking the length of the input string and branching
takes just two extra instructions (slti and a bnez), which is okay
to have in the function preamble because it is not costly.
Wrapping up, the final version is up to 3 times faster than the original Qt implementation, without sacrificing the speed for the rather common small strings.
Last but not least, I would like to thank MIPS Technologies for sponsoring this work, and for making it possible to have a development board at Igalia for testing and benchmarking.